
在评估每种疾病的患病风险时,首先查找国际上对该疾病的研究人群以及样品数量并进行筛选与评估。对于GWAS研究,根据P值、OR值、连锁不平衡系数D’等参数对突变位点进行评估;NGS相关的研究,需要对突变进行基因组注释,筛选有意义的突变,根据疾病数据库和ACMG标准和指南对突变进行分类以及致病风险评估。最后根据评估模型对疾病风险进行评估。评估流程如下图所示。
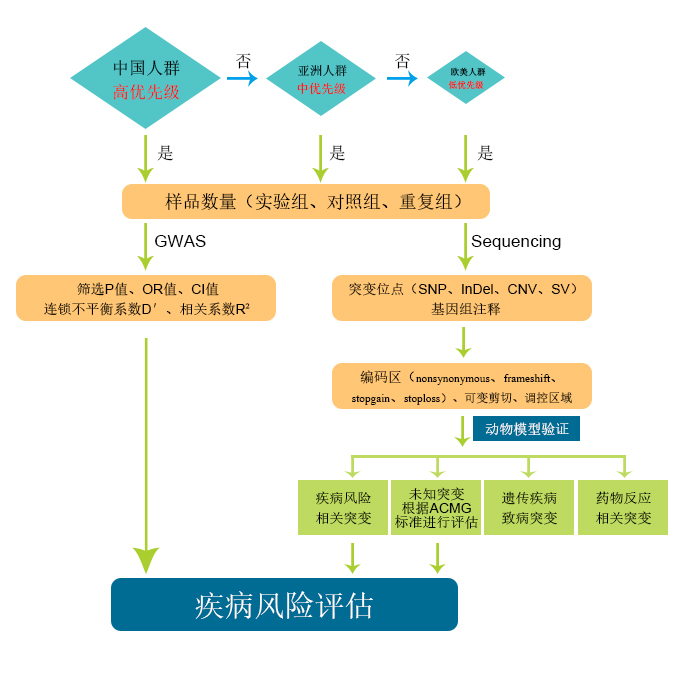
人群筛选和样品数量
在PubMed、LISTA、Web of Science、arXiv等数据库检索疾病与基因相关的文献,根据研究对象,分为中国人群、亚洲人群以及欧美人群等。把中国人群的研究论文归为高优先级,亚洲人群的研究论文归为中优先级,欧美人群归为低优先级。
对于GWAS研究,实验组、对照组、重复组总样品数量要>=1000,小于该阈值,则降低突变的可信程度。对于突变位点需要p<5.0X10-8;对于连锁突变位点,连锁不平衡系数D’≥0.8,相关系数R2≥0.8时,则认为两个SNP之间存在连锁不平衡,此时可仅保留一个tagSNP。
对于测序相关的研究项目,散发疾病需要样品数量>=10,家系样品>=3个家系。WGS测序样品测序深度depth>=30X,WES测序样品测序深度depth>=100,目标区域捕获>=200。
突变位点OR(Odds ratio)值计算
OR值(odds ratio)又称比值比、优势比。是流行病学研究中病例对照研究中的一个常用指标。指病例组中暴露人数与非暴露人数的比值除以对照组中暴露人数与非暴露人数的比值。OR=(a/c)/(b/d)=ad/bc。
| 暴露 | 病例组 | 对照组 |
|---|---|---|
| 有 | a | b |
| 无 | c | d |
突变位点(SNP、InDel、CNV、SV)基因组注释
对于突变位点,需要注释该位点位于基因组上的位置,dbsnp,千人基因组频率,ESP6500频率,Inhouse频率,氨基酸变化,SIFT、Polyphen、MutationTaster、GERP++等多个功能预测。编码区域的非同义突变、移码突变、拷贝数变化、stopgain、stoploss,可变剪切,调控区域,结构变异等突变都是有意义的突变。对于已知的致病突变,可直接参考公共疾病数据库;未知的基因突变,需要根据美国医学遗传学与基因组学学会(ACMG Standards and Guidelines)2015年标准与指南进行评估。下图为ACMG突变分类指南。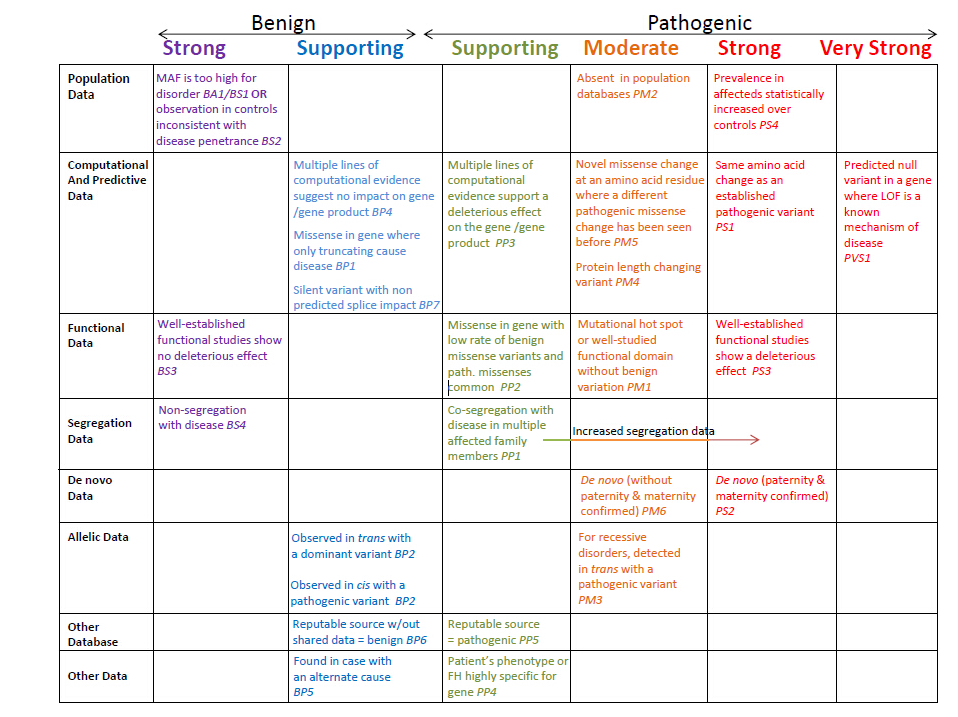
疾病风险评估
单个突变位点导致的疾病
对于单个突变位点导致的疾病,基于疾病在人群或种族中的发病率以及突变位点在人群或种族中的基因型频率,可直接计算该突变导致的疾病风险。其中Pr(D)为疾病发病率,OR为比值比,Pr(G)为基因型频率。

多个突变位点导致的疾病
ORm代表单个SNP的特定基因型的Odds radio,综合所有的突变位点计算出ORc值。ORc*值为带有某些特定基因型组合特征的个体,其患病风险相较于该个体所在种群平均患病风险的比值。odds(D)可以通过Pr(D)(疾病发病率)求出。最终的
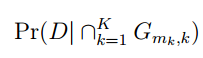
即为多个位点突变导致的疾病风险。
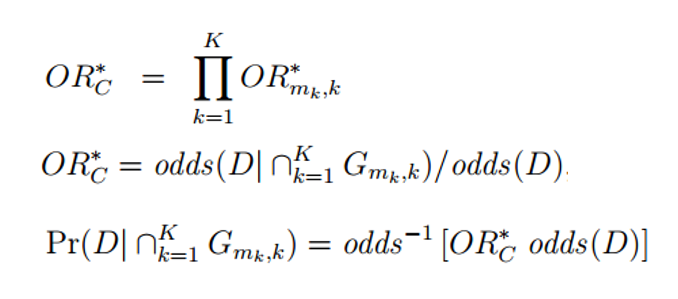
高、中、低、正常疾病风险的说明
高风险:该疾病的相对患病风险高于常人4倍及以上,需要重点关注。可采取的措施包括:
a.定期、针对性的进行临床检查;
b.养成健康的生活方式,避免该疾病有关的风险因素,放松心态,积极参与运动;
c.不乱用药物,减少风险药物的使用;
d.如果家族中有人患有该疾病,需要引起密切关注。
中风险:该疾病的相对患病风险高于常人2倍,但是通常不必过分担心,可以适当关注。
可采取的措施包括:
a.每年体验以排除风险;
b.养成良好的饮食习惯。平时养成不过量摄入肉类、煎蛋、黄油、奶酪、甜食等饮食习惯,少食腌、熏、炸、烤食品,增加食用新鲜蔬菜、水果、维生素、胡萝卜素、橄榄油、鱼、豆类制品等;
c.坚持体育锻炼,保持身心愉悦。
低风险:该疾病的相对患病风险略微高于常人(2倍以内)。健康的生活方式,坚持体育锻炼,积极参加社交活动,避免和减少精神、心理紧张因素,保持心态平和,都能有效降低疾病发生的风险。
正常风险:截止目前为止,该疾病未发现或未收录任何有害突变。
注:疾病的发生是内因(基因、转录本、表观遗传性)和外因(生活、环境)等多种因素决定的。该疾病风险预测只是根据基因数据进行评估,未考虑您的饮食、环境、生活习惯、心理状态等其他因素,因此该风险评估只作为参考,不是临床诊断疾病的依据。
对于有风险的疾病,需结合自己的身体状况、生活环境、家族患病史综合考虑。同时,由于科学研究的局限性,目前的基因评估只是基于现有的基因研究成果,随着科技的发展,疾病风险也会发生变化,我们会根据新的研究成果及时更新相应的疾病基因解读,调整疾病风险。
专业名称解释
全基因组测序(whole genome sequencing)
全基因组测序技术即是对物种所有基因组序列进行测序。全基因组测技术包括提取基因组DNA、随机打断、基因簇制备、对插入片段进行测序等过程。一般人类全基因组测序深度在30层左右。通过全基因组测序可对SNP、InDel、CNV、SV等突变进行分析。
外显子测序(whole exome sequencing)
外显子组测序是指利用序列捕获技术将全基因组外显子区域DNA捕捉并富集后进行高通量测序的基因组分析方法。外显子测序相对于基因组重测序成本较低,对研究已知基因的SNP、InDel等具有较大的优势,但无法研究基因组结构变异等。
SNP
单核苷酸多态性single nucleotide polymorphism。个体间基因组DNA序列同一位置单个核苷酸变异(替代、插入或缺失)所引起的多态性。人基因组上平均约每1000个核苷酸即可能出现1个单核苷酸多态性的变化,其中有些单核苷酸多态性可能与疾病有关,但可能大多数与疾病无关。
InDeL
insertion(插入)和deletion(缺失),基因组上小片段序列的插入或缺失。
CNV
copy number variation,基因组拷贝数变异。基因组拷贝数变异是基因组变异的一种形式,通常使基因组中大片段的DNA形成非正常的拷贝数量。
SV
structure variation,基因组结构变异。染色体结构变异是指在染色体上发生了大片段的变异。主要包括染色体大片段的插入和缺失,染色体内部的某块区域发生翻转颠换,两条染色体之间发生重组等。
测序深度
测序得到的总碱基数与待测基因组大小的比值。
覆盖度
指测序获得的序列占整个基因组的比例。
基因组注释
利用生物信息学方法和工具,对基因组所有基因的生物学功能进行高通量注释,是当前功能基因组学研究的一个热点。基因组注释的研究内容包括基因识别和基因功能注释两个方面。基因识别的核心是确定全基因组序列中所有基因的确切位置。基因功能注释包括,氨基酸变化、dbSNP、人群频率、有害性预测等。

